


|
|
|
Краткое введение в XML |


Взяв любую книгу, вы легко убедитесь, что она оформлена согласно некоторым правилам: (Заголовки/подзаголовки, абзацы, шрифты). Причём, например, говоря о книгах, видим что:
Заметьте, что здесь речь не идёт о содержании какой-то конкретной книги, а только о формальном способе выделения/отображения некоторых информационно-однородных структурных объединений в ней, эквивалентных по семантике, а также отношений между ними. С другой стороны, вы были бы удивлены, если бы в рамках отдельно взятой книги одни и те же семантические объекты имели бы различные представления, а также выражались разными способами отношений между ними. Во всяком случае, это усложнило бы вам восприятие информации.
Другой момент, связан с обработкой структурированной информации, сформированной в одном месте, например на сервере данных, а обрабатываемой в другом, например на конкретном клиенте для просмотра/печати отчёта.
Раздумья над проблемой: "а что же из себя должен представлять документ"? Приводит к мысли о том, что это "триединое понятие" и включает в себя как сами данные, обладающие некоторой структурой, так и указание на способ их визуализации на устройствах отображения. Таким образом, вырисовывается следующая формула:
Документ = Данные + Структура + Представление
Для того, чтобы иметь возможность использовать некоторые структурные различия, мы должны принять соглашения, однозначно понимаемые всеми, кто имеет к этой структурированной информации хоть малейшее отношение. А вот здесь как раз и возникает проблема. {Пример из не столь далёкой истории: с появление текстовых редакторов (MS Word например), где появилось понятие абзаца, практически любому, связанному с работой на компьютере в жизни наверное приходилось "транслировать" такому редактору текст, из редактора, в котором было своё (не оформленное в формальные правила) понимание абзаца (N*0x20 и беспорядочные 0x0D+0x0A вместо одного 0x0D+0x0A в конце абзаца) :)}.
Общеизвестен универсальный формат Reach Text Format (RTF) точнее язык, с помощью которого можно отформатировать печатный документ, используя разнообразия шрифтов, расположить текст, требуемым образом, и добиться того, чтобы печатный документ был близкой копией к оригиналу, просматриваемому в каком-нибудь редакторе. Вот так, к примеру, будет выглядеть в нём такой текст:
Строка в Reach Text Format (RTF)
{\rtf1\ansi\ansicpg1251\deff0\deflang1049{\fonttbl{\f0\fswiss\fcharset204{\*\fname Arial;}Arial CYR;}{\f1\fswiss\fcharset0 Arial;}}
\viewkind4\uc1\pard\f0\fs20\'d1\'f2\'f0\'ee\'ea\'e0\lang1033\f1 \lang1049\f0\'e2\lang1033\f1 \i Reach Text Format \i0 (\b RTF\b0 )\lang1049\f0\par
}
Хм... достаточно разборчиво, не правда ли? :-) Кроме того, что он "птичий" он ещё и "узко специализирован" ничего кроме представления данных для просмотра/печати он не умеет. Не нужно далеко ходить, чтобы привести и другие аналогичные форматы данных: DOC, PDF, ... При создании этих форматов, задачи явного разделение содержимого документов на данные и их структуру не ставилось.
Отсюда возникает понимание того, что нужен язык, который бы:
Служащий подобным целям язык уже существует, и был создан в 1996 году в фирме IBM Research с названием Generalized Markup Language (GML). Язык был разработан для правительственных учреждений в США для обмена информацией между правительственными и государственными учреждениями. Это язык расширяемый, т.е. казалось бы, вопрос языка для этих целей решён. Позднее на него был утверждён стандарт под названием Standard Generalized Markup Language (SGML). Однако, именно из-за своей универсальности он оказался настолько сложен, что практическое применение его вызвало определённые затруднения, в т.ч. и создание ПО для него. Отсюда и высокие цены на продукты, созданные с помощью него (см. http://www.oasis-open.org/cover/).
В связи с бурным развитием Internet общеизвестно распространение другого языка разметки: HTML (http://www.w3.org/MarkUp/) . Этот язык является основным для отображения любых данных в Internet (ANSII стандарт для Internet). Однако, его проблема именно в узкой специализации, направленной на визуализацию данных в Web-browsers. Попробуем обозначить проблемы:
Думаю, что вы легко можете найти и другие, возможно следственные к перечисленным выше проблемам.
В 1996 году консорциумом Word Wide Web ( http://www.w3.org/), была предпринята попытка, приступить к проектированию расширяемого языка разметки, который сочетал бы в себе гибкость и мощность языка SGML и совместимый с распространенностью HTML. Этот язык получил название (Extensible Markup Language) XML (http://www.w3.org/XML/). А в феврале 1998 был принят стандарт этого языка как XML 1.0 в качестве рекомендаций W3C. В настоящий момент существует выпущенная 6 октября 2000 года Extensible Markup Language (XML) 1.0 (Second Edition) рекомендация консорциума W3C (http://www.w3.org/TR/REC-xml). См. также:
В настоящий момент фирма Microsoft® начинает широко применять язык XML при работе со структурированными данными в своих продуктах.
Ниже коротко рассматривается определения и синтаксические конструкции этого языка. Это оказалось трудным расположить так информацию, чтобы в порядке прямого её чтения не встречалось ни одного термина, который был бы не разъяснённым предварительно. Поэтому, если при чтении у вас возникнут подобные затруднения, не смущайтесь, читайте дальше. Просто при разборе соответствующей синтаксической конструкции или понятия вернитесь назад, чтобы уточнить соответствующее понятие.
К числу символов, допустимых в XML-документах относятся все три управляющих C0 символа стандарта ANSII, все обычные символы этого стандарта, и почти все символы Unicode:
|
Значение (в hex) |
Описание |
| 09 | Горизонтальная табуляция (HT) |
| 0A | Перевод строки (LF) |
| 0D | Возврат каретки (CR) |
| 20..7E | Символы ANSII |
| 80..D7FF | Символы Unicode (включая Latin-1) |
| E000..F8FF | "Область частного использования" |
| F9..FFFD | Идеограммы совместимости с CJK (китайским-корейским-японским языками) |
| 10000..10FFFF | Суррогатные эквиваленты и "область исключительного частного использования" |
В XML имеется ряд символов, за которыми закреплена особая роль в обработке анализаторами, поэтому наложены определённые ограничения на их использование в XML-документах. Вот их список:
|
Символ |
Значение (в hex) |
Обозначение (в коде) |
Назначение |
| < | < | < | Ограничитель разметки |
| > | > | > | Ограничитель разметки |
| & | & | & | Ссылка |
Структуры в XML почти всегда именованы. Любое имя должно начинается с буквы, знака подчёркивания ('_') или двоеточия (':') и продолжается только из допустимых в XML для имён символов, которые не обязательно ограничены ANSII символами, а также могут включать в себя буквы национальных алфавитов. Имена не могут начинаться со строки 'xml' причём в любой комбинации заглавных/прописных букв. Также нужно иметь ввиду, в отличии от HTML-документа, названия, как и почти вся информация XML-документа чувствительна к регистру. Далее, в значениях атрибутов, могут быть использованы так называемые nmtoken (name token) имена, определённые средствами DTD и могут представлять собой любую смесь символов, без ограничений на первый символ. Наконец, для исключения проблемы одинокого именования логически разных объектов вводится понятие пространства имён и расширенного имени.
Имена, могут принадлежать пространствам имён (Namespaces). Это снимает проблему использования одинаковых имён, но различающихся т.с. логически. Таким образом, в XML вводится понятие расширенного имени (например: 'xsl:stylesheet'), которое состоит из локального имени ('stylesheet') + имени пространства имён ('xsl'), которому это имя принадлежит. Локальное имя отделяется от префикса пространства имён символом двоеточия ':'. Расширенные имена считаются совпадающими, если совпадают их локальные имена, и они принадлежат одному и тому же пространству имён. В примере ниже показано как объявляется пространство имён в двух возможных формах:
<xsl:stylesheet xmlns:xsl="http://ww.w3.org/1999/XSL/Transform"> </xsl:stylesheet> <!-- явное --> <stylesheet xmlns="http://ww.w3.org/1999/XSL/Transform"> </stylesheet> <!-- по умолчанию -->
Нужно также иметь ввиду, что:
Чтобы дать возможность использовать чего-нибудь, что неопределенно в рамках языка, предусмотрена возможность создания собственных (т.е. внешних по отношению к языку) определений и их использования. Ссылка всегда начинается знаком амперсанта '&' и завершается точкой с запятой ';'. В XML имеется два вида ссылок:
Ссылки на символы в XML используют там, где в противном случае возникает нарушение ограничений, налагаемых анализатором. Ссылка на символ (character reference) представляет из себя последовательность цифр в десятичном или шестнадцатеричном формате, закачивающуюся точкой с запятой ';' и перед которой стоит знак '&'. Так, например, в виде десятичного (&#...;) или шестнадцатеричного (&#x...;) числа ссылки:
будут отображаться в Web-browser как символ: '(©)'.
Ссылки на сущность позволяет включать любые строковые константы в содержание элементов или значения атрибутов, а также представляют мнемонические альтернативы ссылкам на символы. Ссылки на сущность представляется разрешенным к использованию в XML именем, перед которым стоит знак амперсант '&', а после - точка с запятой ';'. Например:
&name;
Пять сущностей предопределены в XML и используются вместо символов разметки XML:
|
Сущность |
Применение |
| & | Всегда используется вместо знака амперсант '&'. Исключение составляют разделы CDATA |
| < | Всегда используется вместо вместо символа '<'. Исключение составляют разделы CDATA |
| > | Может использоваться вместо символа '>'. В разделе CDATA объект всегда необходимо использовать, если за знаком '>' следует строковая константа "]]" |
| ' | Может использоваться вместо символа ' в строковой константе |
| " | Может использоваться вместо символа " в строковой константе |
Все другие сущности должны быть определены перед их использованием. Сущности могут определяться:
Если при замещении имени на значение возникнет необходимость применения значения другой, встретившейся при этом сущности, то замещение должно продолжаться пока все сущности не будут заменены. Тем не менее, "имя" не должно содержать рекурсивных ссылок на себя, прямо или косвенно.
Символьные данные - это любой текст, являющийся содержанием документа. Однако за двумя символами: '<' и '&' в языке XML закреплена особая роль (см. раздел Зарезервированные символы выше):
это так называемые защищённые в XML символы, и поэтому они не могут входить в состав символьных данных. При необходимости включения этих символов в состав символьных данных следует:
Разделы CDATA представляют собой способ включения в документ текста, который иначе бы интерпретировался бы анализатором как разметка. Обычно такая потребность возникает для включения в текст документа примеров, содержащих разметку, или кода функций на каком-нибудь языке программирования. Базовый синтаксис раздела CDATA такой:
<![CDATA[...]]>
где '...' - может содержать любую последовательность символов, исключая: ']]>'
Обратите внимание, что раздел CDATA не лучший способ включения в XML-файл фрагмента двоичных данных. Проблема может возникнуть из-за присутствия последовательности из трёх байт: '5D 5D 3E' непосредственно в таких данных.
В XML используются строковые значения, однако при этом имеются определённые ограничения на них.
Под пустыми пространствами (white space) в XML понимают данные, содержащие четыре символа:
|
Значение (в hex) |
Описание |
| 09 | Горизонтальная табуляция (HT) |
| 0A | Перевод строки (LF) |
| 0D | Возврат каретки (CR) |
| 20 | Символ пробела ANSII |
В спецификациях XML требуется, чтобы анализатор передавал все символы, в т.ч. и эти приложению. Таким образом, приложение должно само обрабатывать эти символы, а правило по обработке пустых пространств, в XML чрезвычайно просто:
Следует иметь в виду, что при обработке HTML-документов в Web-browser-ах удаляются все символы пустых пространств и заменяются одним пробелом. И для предотвращения уничтожения вашей разметки следует использовать
Существует три взгляда по обработке концов строк (End-of-Line Handling). За конец строки принимать:
чтобы упростить обработку XML анализаторы все последовательности, обозначающие концы строк преобразуют в один символ LF. Это нравится программистам под Unix и огорчает программистов под MS Windows. Но пока это именно так.
XML-документы во многом внешне (по формату) схожи с HTML-документами. Любая информация XML-документа помещается в теги (tag). Тег всегда начинается с символом '<' а завершается '>' Сразу за символом началом тега (знаком '<') следует название тега. На возможные названия тега наложено ряд ограничений (см. подробности в разделе Имена данного документа). Если "содержание" тега не является пустым, то в отличии от требований HTML-формата, сразу за содержанием должен следовать закрывающий тег (end-tag). Закрывающий тег - это точная копия открывающего, но сразу за символом начала тега ('<') должен следовать символ деления ('/'). Вот простой пример:
<Title>Название</Title>
Далее, точно также как и в HTML-формате, тег может иметь атрибуты со своими значениями (подробности см. ниже). Вот пример, в котором показан тег с именем Header, имеющий атрибуты Alignment со значением Center и Font со значением Arial:
<Header Alignment="Center" Font="Arial"> Заголовок </Header>
Наконец, если "содержание" тега отсутствует, то и закрывающий тег может отсутствовать, но при условии, что в открывающем теге перед символом закрытия тега '>' имеется символ '/'. Вот пример тега без "содержания":
<IMG SRC="Pick.gif" />
Ещё раз обратите внимание, что допустимый в HTML тег: <HR> в XML вызовет ошибку, и правильное его написание в XML имеет вид: <HR />
Выше при рассмотрении тега был, упомянут атрибут. Давайте рассмотрим его по подробнее. Часто требуется связать некоторую информацию с некоторым блоком данных, а не просто включить эту информацию в качестве содержания этих данных. Это делается с помощью атрибутов, представляемых в виде пар: имя-значение.
attribute_name="attribute_value" или attribute_name='attribute_value'
В XML на значения атрибутов наложен ряд ограничений:
Иногда непосредственно в текст документа полезно включать комментарий, поясняющий содержание документа, или другие метаданные. Комментарий может появляться в любом месте документа вне другой разметки. Ограничение на его применение таково, что он не может появляться внутри тегов и значений атрибутов. Синтаксис комментария следующий:
<!-- Текст комментария -->
Т.к. XML является описательным языком разметки, то не предполагается, что будет объясняться: как именно следует обрабатывать элементы документа и его содержание. Однако, иногда требуется совместно с документом, но ещё до его обработки, придать некоторые пояснения для работы с документом в целом. Механизм этого процесса реализуется через так называемые команды обработки (Processing Instructions PI). Это команды имеют синтаксис:
<?target ...instruction... ?>
Первое (target) - это любое допустимое в XML имя, указывающее на приложение, которому адресована инструкция, сама же инструкция, достаточно произвольна.
Для приложения XML в команды обработки помещают XML-декларации (XML Declaration), с помощью которых, обычно указывают:
Например:
<?xml version = "1.0" encoding="Windows-1251" standalone="yes"?>
здесь указаны:
Замечания:
Список распространённых значений атрибута encoding для России может быть таким:
Другая информация, помещаемая в PI - ссылка на таблицу стилей, с помощью которой будет обрабатываться содержание документа:
<?xml-stylesheet type= "text/[css|xsl]" href="..." [charset="..."] [title="..."] [media="..."]?>
Например:
<?xml-stylesheet type="text/xsl" href="my.xsl" charset="Windows-1251"?>
В первой версии XML для определения логической структуры документа использовался набор формальных правил, называемых Document Type Definition (DTD). Существует два типа деклараций:
В последнем случае имеется две различных возможности осуществить ссылку на внешнее определение - это с использованием ключевых слов SYSTEM или PUBLIC. Например:
<!DOCTYPE MyDoc SYSTEM "http://MyServer/MyDefs/MyDoc.dtd">
<!DOCTYPE MyDoc PUBLIC "universal/Pub/Defs"
"http://www.universal/Pub/CommonDocs.dtd">
В случае с PUBLIC имеется ввиду "хорошо известный" ресурс, а скорее всего просто известный стандарт. (См. также: http://www.w3.org/TR/REC-xml#dt-doctype - The XML document type declaration).
Оперируя такими командами как:
<!DOCTYPE...>, <!ENTYTY...>, <!ELEMENT ...>, <!ATTLIST...>, <!NOTATION ...>, ...
язык DTD позволяет определить логическую структуру документа. Т.е.
Более подробно см. Введение в язык определения типов Document Type Definition (DTD)
Однако этот язык обнаружил в себе и существенные проблемы:
Для преодоления проблем DTD, в начале мая 2001 была принята новая техническая рекомендация под названием XML-схема (XML Schema) (http://www.w3.org/TR/NOTE-xml-schema-req). В целях развития этой технологии W3C консорциумом была создана группа под названием XML Schema Working Group, и в сентябре 2001 года рекомендация была пересмотрена (http://www.w3.org/TR/xmlschema-formal/). (См. разработки по XML-Data Reduced (XDR), языка используемого для создания XML-схем (http://www.ltg.ed.ac.uk/~ht/XMLData-Reduced.htm). а также язык определений XML-схем Schema definition language (XSD) (http://msdn.microsoft.com/library/default.asp?url=/library/en-us/xmlsdk/htm/xsd_ref_7gh1.asp). В настоящий момент фирма Microsoft® начинает широко применять XML-схемы для описания структуры и межтабличных отношений в своих продуктах.
Заключённая в открывающий и закрывающий теги информация (вместе с тегами) называется элементом (См. также раздел Тег данного документа). Элемент может включать в себя:
и всё это вместе называется содержанием элемента (element contents).
Понятие того, как элемент может включать в себя другие элементы, требует уточнения: элементы должны быть "правильно" вложенными. Т.е. начальный тег, будучи помещённый в некоторый родительский, должен иметь в этом же теге и концевой. Другими словами, конструкции с "общими пересечениями", типа:
<A><B></A></B>
недопустимы. Здесь "неправильным" является то, что участок <B></A> принадлежит одновременно как <A></A> так и <B></B>. Запрет на подобные пересечения автоматически означает, что структура данных, помещаемых в элементы имеет строго иерархическую структуру, или другими словами: каждый элемент имеет строго одного "непосредственного родителя".
Получив сведенья о различных синтаксических конструкциях, перейдём к рассмотрению общей логической структуры документа. Любой XML-документ оформляется согласно следующей структуре:
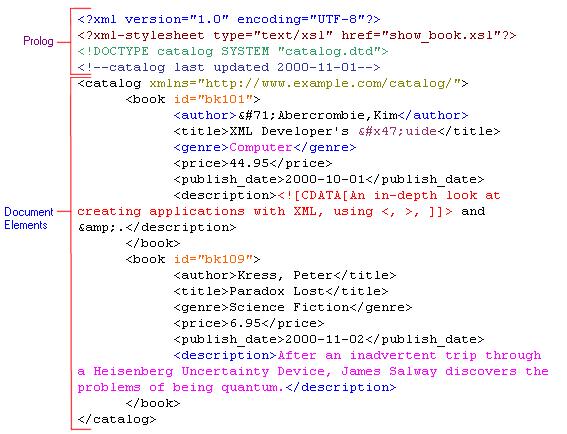
Т.е. состоит из трёх разделов:
Любой XML документ начинается с пролога. В пролог помещается описательная информация для всего документа в целом, которую требуется получить анализатору ещё до начала какой-нибудь обработки документа. К ней относятся:
Пролог не является обязательной частью XML-документа, в том смысле, что его отсутствие не должно вызывать каких-нибудь проблем у анализаторов. Необязательность пролога продиктована лишь совместимостью с GML и HTML в версиях, существовавших до выхода XML. Если бы пролог был обязателен, то документы в GML и HTML прежних версиях перестали бы быть хорошо оформленными (объясняется ниже). Однако, правилом хорошего тона считается всегда помещать пролог в любой XML-документ.
Пролог организационно включается в Корень документа.
Тело документа собственно и включает в себя прикладную информацию и должно состоять ровно из одного узла, называемого элементом документа (element document). С точки зрения иерархической структуры данных, все другие прикладные данные обязаны быть детьми одного единственного элемента документа (См. таже раздел Элемент данного документа).
Тело документа организационно включается в Корень документа.
Эпилог завершает XML-документ и не является обязательным, однако если он имеется в документе, то может состоять только из комментариев.
Организационно, и Пролог и Тело документа включаются в так называемый Корневой узел или Корень документа, который обычно обозначают одиночным символом деления: '/'. Любой анализатор начинает разбор XML-документа именно с этого корневого узла. Так что реальная схема документа может быть представлена следующим образом:
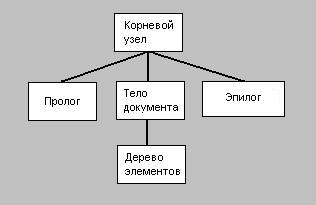
В соответствии со спецификациями XML все документы делятся на две группы:
Все документы, соответствующие спецификациям XML называются правильно оформленные документы (well-formed), если они могут быть использованы без Декларации типа документа (DTD) или XML-схем (XML Schema). Другими словами, такие документы не могут использовать внешние декларации, а атрибуты не подвергаются специальной обработке и не имеют значений по умолчанию. Таким образом, чтобы XML-документ был правильно/хорошо оформленным, должны быть выполненными следующие условия:
Документ называется состоятельным, если он Правильно оформленный (well-formed) и имеет внешние определения в виде деклараций типа документа (DTD), т.е. не может быть корректно обработан без привлечения "внешней информации", или у него могут быть предопределены сущности и/или атрибуты с использованием внутренних деклараций типа документа.
Существуют два типа анализаторов:
По способу своей работы анализаторы также делятся на два разных типа:
Принцип работы такого типа анализатора основан на обращениях к функциям обратного вызова (call-back) обрабатывающего приложения всякий раз, когда при обработке документа начата/завершена обработка какой-нибудь структурного объекта документа: элемента, атрибута, символьных данных, команды обработки, нотации или комментария. Программирование же приложения заключается в написании реализация этих самых функций обратного вызова, чтобы выполнить требуемую обработку. Такие анализаторы не обслуживают работу с иерархической структурой данных как таковой, а просто последовательно читают документ, генерирую соответствующие события и, передавая информацию об объекте, который был почитан.
Ниже представлена схема работы такого анализатора фирмы Microsoft®
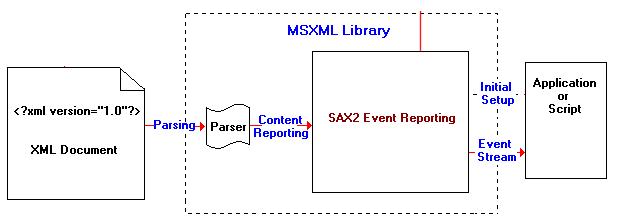
Устоявшееся общепринятое название для подобных анализаторов: Simple API for XML (SAX) (http://www.saxproject.org/). К их достоинствам можно отнести как компактность, так и очень высокую скорость работы, с которой они способны обработать даже очень большие XML-документы.
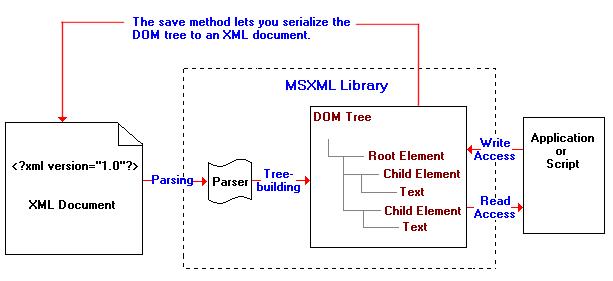
Данные XML-документа по структуре представляют собой иерархическое дерево. Поэтому при путешествии по узлам, поиске его содержания или редактировании можно использовать хорошо разработанные алгоритмы. Для осуществления этой задачи, консорциум W3C разработал объектную модель документа Document Object Model (DOM), (http://www.w3.org/DOM/). Эта модель представляет собой независимый от языка или платформы интерфейс, позволяющий совершать весь необходимый набор манипуляции с деревянной структурой XML-документа.
Особенность древовидных анализаторов такова, что дерево XML-документа они выстраивают в памяти компьютера, и для больших документов для этого требуется высокопроизводительная поддержка работы с виртуальной памятью компьютера. Далее, через соответствующее API приложение может осуществлять навигацию по иерархическим данным документа, производить поиск, редактирование и другие операции над данными.
Ниже представлена схема работы такого анализатора фирмы Microsoft®
Чтобы продемонстрировать: как можно получить XML-представления в реляционных базах данных, приведём пару коротеньких кода-примера.
Пример получения xml+xsd-файлов в VFP 7.0
*
*********************************************************************
* Author: Michael Drozdov
* Description: Example convert dbf-file into xml/xsd-liles
* by means VFP 7.0 (SP1VFP7)
* E-mail: Mailto:Drozdov@ics.perm.su
* My Page: http://vfpdev.narod.ru/
* Date: 06/20/2003
*********************************************************************
*
#DEFINE C_PATH Home(2)+"Data\"
#DEFINE C_TABLE C_PATH+"products.dbf"
#DEFINE C_PATHLIB Home()+"ffc\"
#DEFINE C_ENVIRLIB "_environ.vcx"
#DEFINE C_SHEXECLS "_shellexecute"
#DEFINE C_SHOPERAT "open"
*
*-- Open dbf-file
LOCAL lcAlias As String, lbOpen As Boolean
lcAlias = Proper(JustStem(C_TABLE))
IF !Used(lcAlias)
USE (C_TABLE) IN 0 SHARED
IF !Used(lcAlias)
= MessageBox('Can not open file: '+C_TABLE, 16, _SCREEN.Caption)
RETURN .F.
ENDIF
lbOpen = .T.
ENDIF
SELECT (lcAlias)
*
*-- CursorToXML
LOCAL lnRetLen As Number, lcPathOut As String
lcPathOut = Lower(Addbs(SYS(2023)))
SET SAFETY OFF
lnRetLen = CursorToXML(lcAlias, lcPathOut+lcAlias+".xml";
,3, 8+16+512, 0, lcPathOut+lcAlias+".xsd")
SET SAFETY ON
*
*-- Try Show result
LOCAL lbRetVal as Boolean, lcOutFile As String
lcOutFile = lcPathOut+lcAlias+".xml"
IF File(lcOutFile)
*
*-- XML-file exist
LOCAL loSHExe
loSHExe = NewObject(C_SHEXECLS, C_PATHLIB+C_ENVIRLIB)
IF Vartype(loSHExe) = 'O'
LOCAL lnRetCode As Number
*
*-- Try Show result
lnRetCode = loSHExe.ShellExecute(lcOutFile, '', C_SHOPERAT)
IF lnRetCode > 32
lbRetVal = .T.
ELSE
= MessageBox('Error:' + Ltrim(Str(lnRetCode))+Chr(13)+Chr(10);
+ 'Can not open file: '+lcOutFile, 16, _SCREEN.Caption)
ENDIF
loSHExe = NULL
ENDIF
CLEAR DLLS
ENDIF
*
*-- Close dbf-file if need
IF lbOpen AND Used(lcAlias)
LOCAL lcDbc As String
lcDbc = CursorGetProp("Database", lcAlias)
USE IN (lcAlias)
*
*-- Close dbc-file if exist
IF !Empty(lcDbc) AND DBused(lcDbc)
SET DATABASE TO (lcDbc)
CLOSE DATABASES
ENDIF
ENDIF
RETURN lbRetVal
Выдержка из результата выполнения представлена ниже:
<?xml version="1.0" encoding="Windows-1252" standalone= "yes"?> <VFPData xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="c:\docume~1\michael\locals~1\temp\Products.xsd"> <row product_id="1" prod_name="Chai" eng_name="Dharamsala Tea" no_in_unit="10 boxes x 20 bags" unit_price="18.0000" unit_cost="16.3800" in_stock="39.000" on_order="0.000" reorder_at="10.000" discontinu="false" /> <!-- ...[ other contents skip]... --> <row product_id="77" prod_name="Original Frankfurter grune So?e" eng_name="Original Frankfurter Green Sauce" no_in_unit="12 boxes" unit_price="13.0000" unit_cost="11.8300" in_stock="32.000" on_order="0.000" reorder_at="15.000" discontinu="false" /> </VFPData>
Пример на C#, делающий выборку из таблицы базы данных MS SQL Server 2000.
//*
//*********************************************************************
//* Author: Michael Drozdov
//* Description: Example execute SQL-select into xml
//* by means C# from MS SQL Server 2000
//* E-mail: Mailto:Drozdov@ics.perm.su
//* My Page: http://vfpdev.narod.ru/
//* Date:
06/20/2003
//*********************************************************************
//* using
System; using
Microsoft.Data.SqlXml; using
System.IO; namespace
Test1
{ class
Test
{ static string NorthwindConnString="Provider=SQLOLEDB;Server=(local);database=Northwind;Integrated Security=SSPI";
public static int testParams()
{
Stream strm;
SqlXmlParameter p;
SqlXmlCommand cmd = new SqlXmlCommand(NorthwindConnString);
cmd.CommandText = "SELECT FirstName, LastName, BirthDate FROM Employees WHERE LastName=? For XML Auto";
p = cmd.CreateParameter();
p.Value = "Fuller";
string strResult;
try
{
strm = cmd.ExecuteStream();
strm.Position = 0;
using(StreamReader sr = new StreamReader(strm))
{
Console.WriteLine(sr.ReadToEnd());
}
}
catch (SqlXmlException e)
{
//in case of an error, this prints error returned.
e.ErrorStream.Position=0;
strResult=new StreamReader(e.ErrorStream).ReadToEnd();
System.Console.WriteLine(strResult);
}
return 0;
}
}
///
/// Summary description for Class1.
///
class Class1
{
///
/// The main entry point for the application.
///
[STAThread]
static void Main(string[] args)
{
Test.testParams();
}
}
}
Результат выполнения:
<Employees FirstName="Andrew" LastName="Fuller" BirthDate="1952-02-19T00:00:00"/>
См. также:

|
По вопросам, связанным с этим веб-узлом, обращайтесь по адресу:
 © Michael Drozdov, 2000-2006. Все права защищены. Последнее изменение страницы: Сб, 28 января 2006 |
|